DATA
The PLEC corpus contains samples of learner English, such as essays, letters, MA theses and many other types written compositions authored by Poles using English as a foreign language (2.8 million words in total). It also features a 200 000 word time-aligned spoken subcorpus of learner English.
Digitization
The process of acquiring learner data for the corpus is fairly complex. First of all, language data has to be digitized, which in the case of written texts may involve the scanning, optical character recognition or even manual transcription, normalization and structural annotation of different types of written language. The figure below shows a typical piece of handwritten text that could be included in the PLEC:

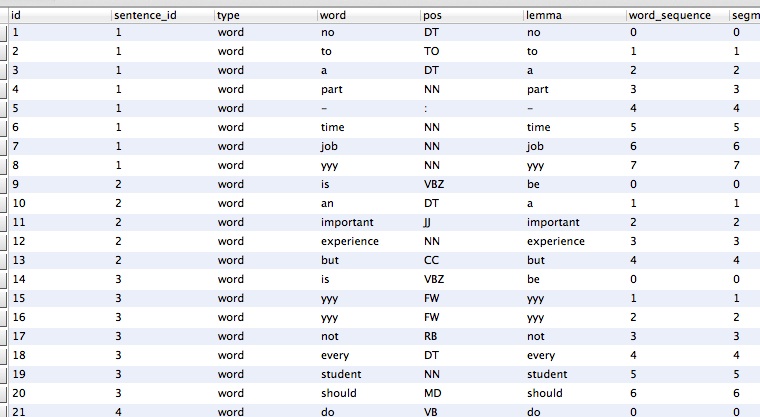
Converting this text to a database format where each word is annotated with syntactic information is obviously a time-consuming process. Only some of this work can be done automatically, and it may come at the expense of precision. For example, the part-of-speech tags assigned to each word in the PLEC corpus are not always correct, but they still allow the users of the corpus to run more generic queries on the learner data. The data collected within the project is not merely transcribed but also annotated at different structural, bibliographic and linguistic levels.
Spoken data acquisition
Even more tricky is the collection and digitization of spoken learner data. Conversations have to be arranged and carried out with volunteers. The resulting high quality recordings are transcribed, time aligned and annotated for selected types of pronunciation errors and other aspects of spoken discourse.
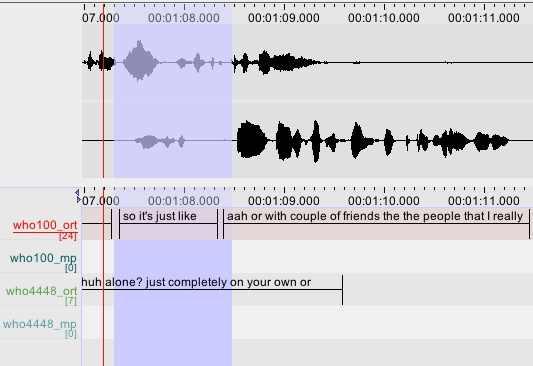
The figure above shows some of the annotation tiers which are specific to the spoken component of the corpus. Annotators map the boundaries of utterances to the sound track and thus each utterance can be traced back to the respective speakers.